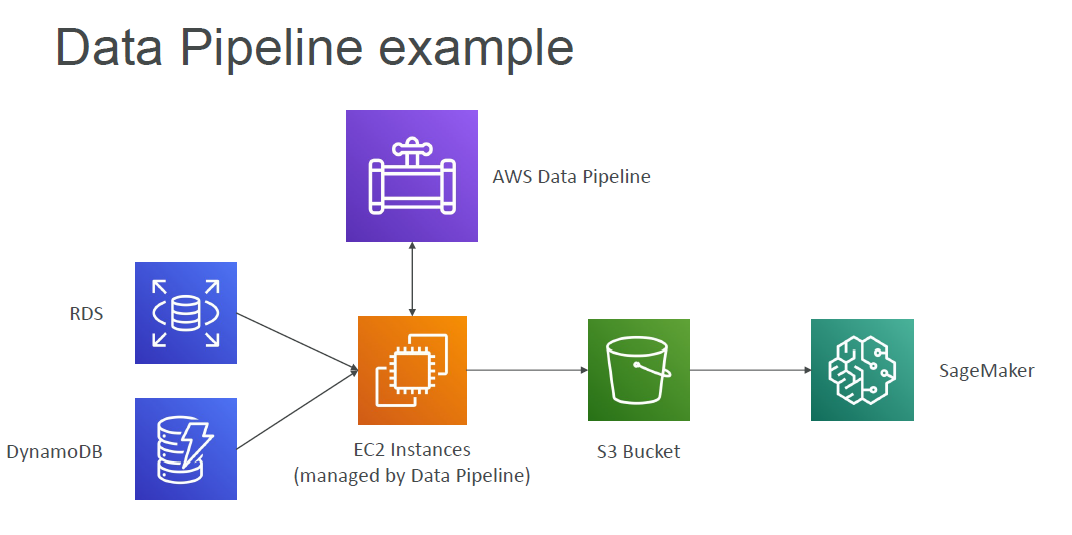
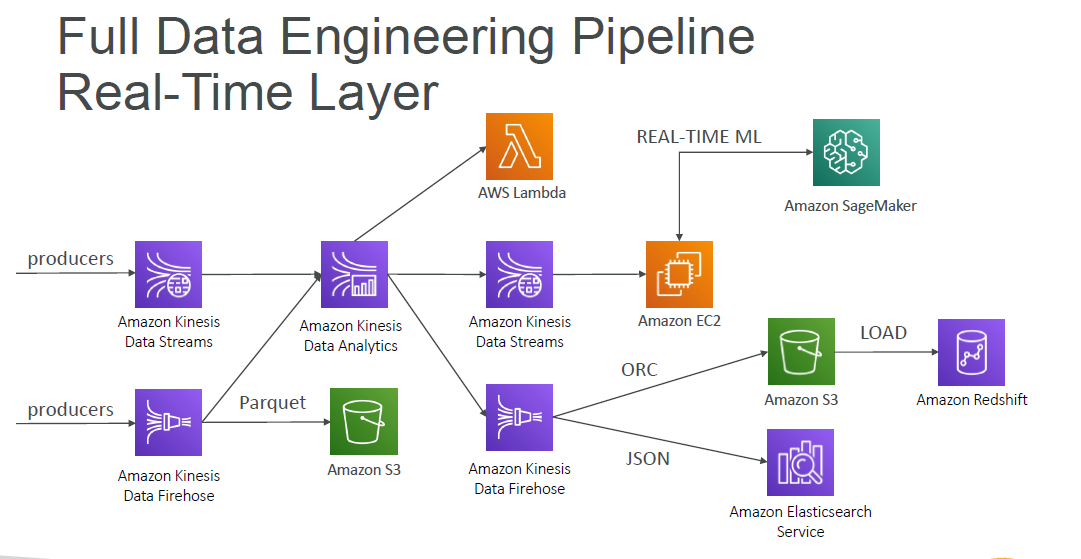
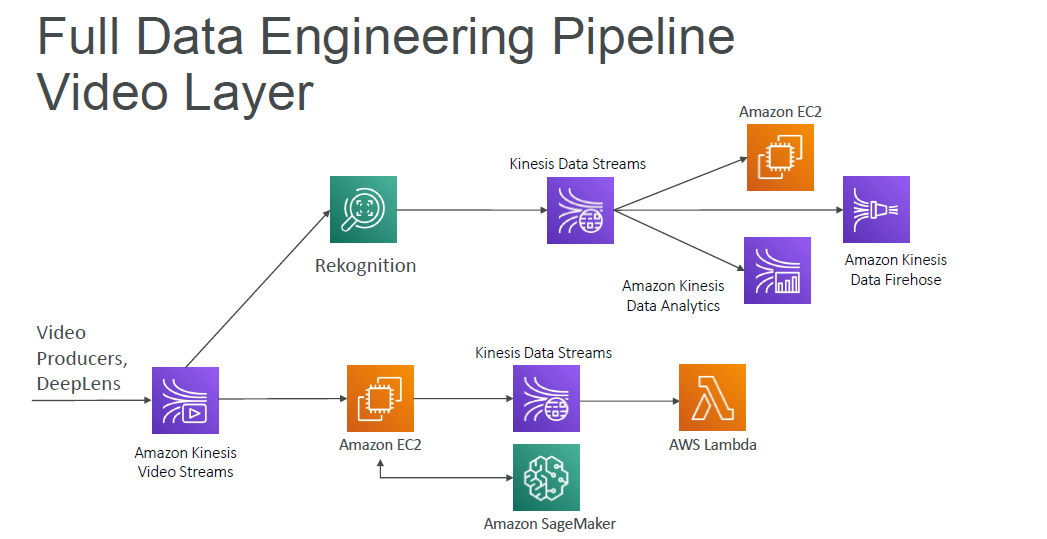
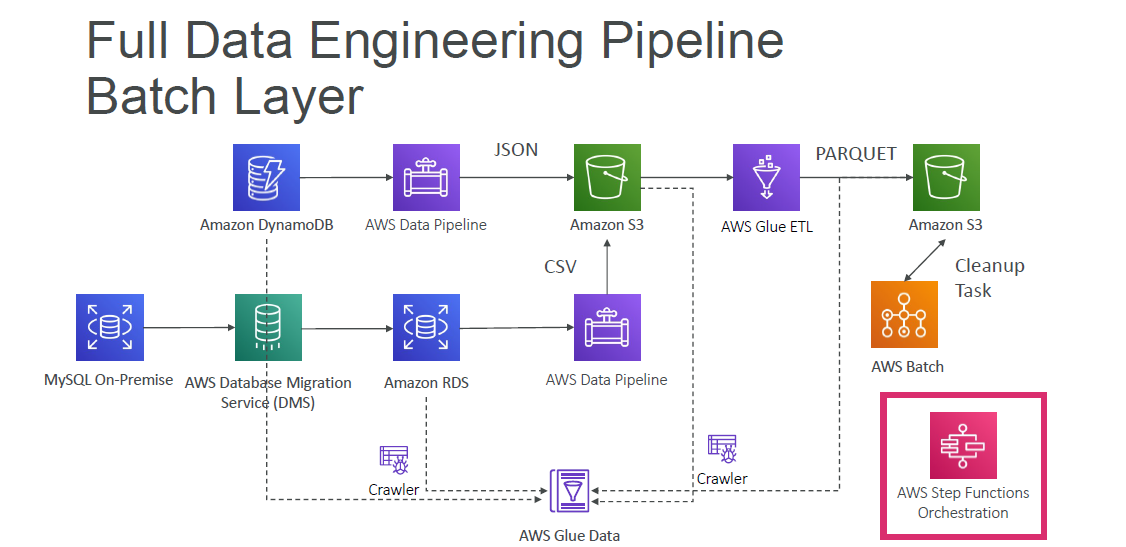
Data Engineering
Data Engineering
S3
S3 Storage Classes
- S3 Standard: For general-purpose storage of frequently accessed data; designed for durability of 99.999999999% of objects over a given year.
- S3 Intelligent-Tiering: Designed to optimize costs by automatically moving data to the most cost-effective access tier, without performance impact or operational overhead.
- S3 Standard-IA: For long-lived, infrequently accessed data that needs to be accessed rapidly when needed.
- S3 One Zone-IA: For long-lived, infrequently accessed, non-critical data.
- S3 Glacier: For long-term archive and digital preservation.
- S3 Glacier Deep Archive: For long-term archive and digital preservation with retrieval times in hours.
Lifecycle Policies
-
Transition Actions: Define when objects transition to another storage class. For example, you might choose to transition objects to the S3 Standard-IA storage class 30 days after you created them, or archive objects to the S3 Glacier storage class one year after creating them.
-
Expiration Actions: Define when objects expire. For example, you might choose to expire objects in the S3 Standard storage class 365 days after creating them.
-
Noncurrent Version Transition Actions: Define when noncurrent object versions transition to another storage class. For example, you might choose to transition noncurrent object versions to the S3 Standard-IA storage class 30 days after creating them, or archive noncurrent object versions to the S3 Glacier storage class one year after creating them.
-
Noncurrent Version Expiration Actions: Define when noncurrent object versions expire. For example, you might choose to expire noncurrent object versions in the S3 Standard storage class 365 days after creating them.
S3 Encryption
-
S3-Managed Keys (SSE-S3): Amazon S3 encrypts each object with a unique key. As an additional safeguard, it encrypts the key itself with a master key that it regularly rotates. Amazon S3 server-side encryption uses one of the strongest block ciphers available, 256-bit Advanced Encryption Standard (AES-256), to encrypt your data.
-
AWS Key Management Service (SSE-KMS): With AWS Key Management Service (AWS KMS), you can centrally create, manage, and delete the keys used for server-side encryption. AWS KMS is integrated with several AWS services to make it easy to encrypt the data you store in these services.
-
Customer-Provided Keys (SSE-C) : You manage the encryption process, the encryption keys, and related tools. You are responsible for protecting the encryption keys you use to protect your data.
S3 Versioning
- Versioning: Versioning is a means of keeping multiple variants of an object in the same bucket. You can use versioning to preserve, retrieve, and restore every version of every object stored in your Amazon S3 bucket. With versioning, you can easily recover from both unintended user actions and application failures.
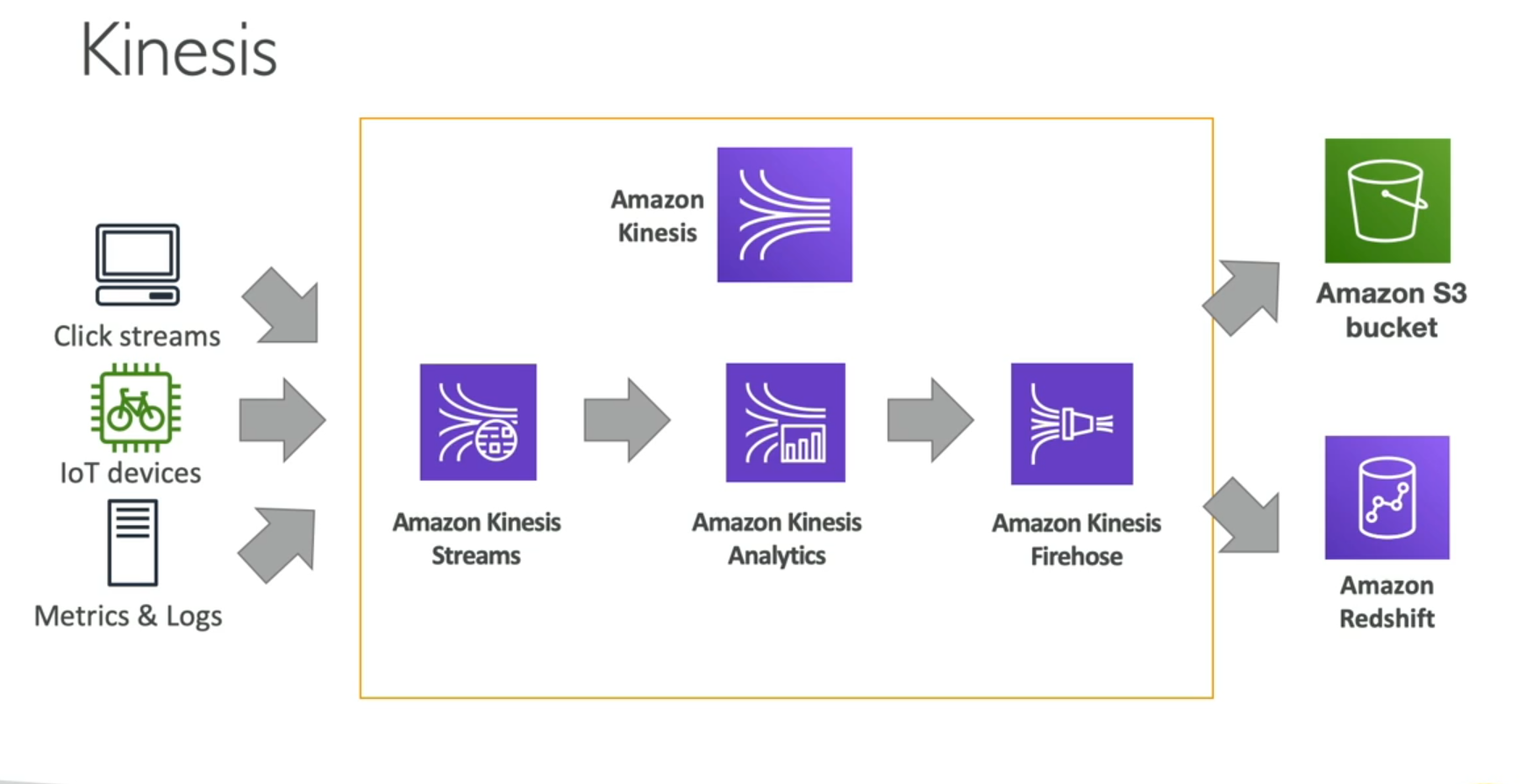
AWS kinesis Overview
kinds of Kinesis
-
Kinesis Data Streams: Kinesis Data Streams is a massively scalable and durable real-time data streaming service. It can continuously capture gigabytes of data per second from hundreds of thousands of sources such as website clickstreams, financial transactions, social media feeds, IT logs, and location-tracking events.
-
Kinesis Data Firehose: Kinesis Data Firehose is the easiest way to reliably load streaming data into data stores and analytics tools. It can capture, transform, and load streaming data into Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, and Splunk, enabling near real-time analytics with existing business intelligence tools and dashboards you’re already using today.
-
Kinesis Data Analytics: Kinesis Data Analytics is the easiest way to process and analyze streaming data in real time with standard SQL without having to learn new programming languages or processing frameworks. Kinesis Data Analytics enables you to query streaming data or build entire streaming applications using SQL, so that you can gain actionable insights and respond to your business and customer needs promptly.
-
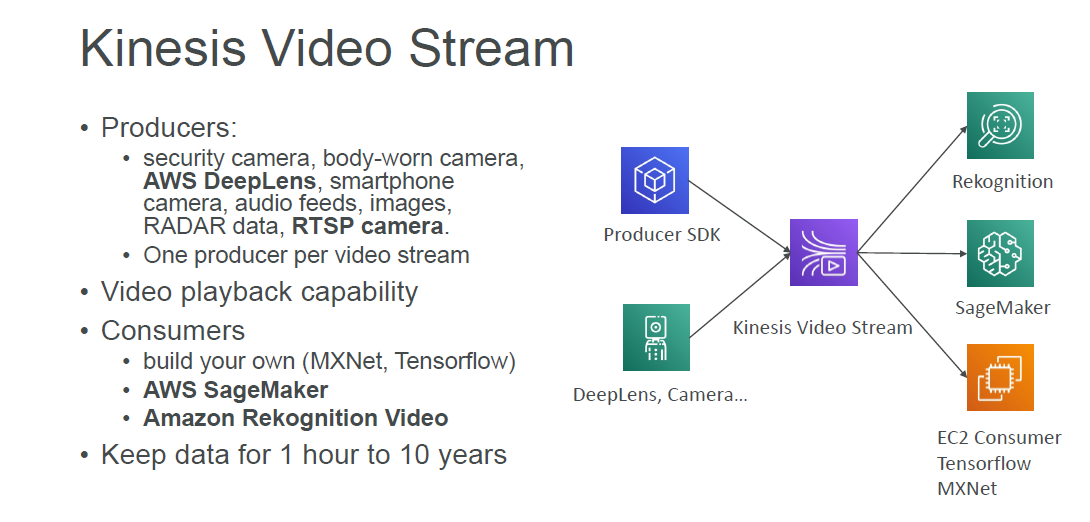
Kinesis Video Streams: Kinesis Video Streams makes it easy to securely stream video from connected devices to AWS for analytics, machine learning (ML), and other processing. Kinesis Video Streams automatically provisions and elastically scales all the infrastructure needed to ingest streaming video data from millions of devices. It also durably stores, encrypts, and indexes video data in your streams, and allows you to access your data through easy-to-use APIs.
Kinesis Data Streams
Provisioned mode: In this mode, you need to specify the number of shards while creating the stream. You can increase or decrease the number of shards in the stream as per your requirement.
- You choose the number of shards when you create the stream.
- Each shard gets a capacity of 1MB/sec data input and 2MB/sec data output.
- You pay per shard-hour and for the amount of data you ingest and the amount of data you read from the stream.
On-demand mode: In this mode, you don’t need to specify the number of shards while creating the stream. Kinesis Data Streams automatically scales the number of shards based on the amount of data in the stream.
- You don’t need to specify the number of shards when you create the stream.
- Kinesis Data Streams automatically scales the number of shards based on the amount of data in the stream.
- You pay for the amount of data you ingest and the amount of data you read from the stream.

Kinesis Streams Overview
- Streams are divided in ordered Shards / Partitions
- Data retention is 24 hours by default, can go up to 365 days
- Ability to reprocess / replay data
- Multiple applications can consume the same stream
- Once data is inserted in Kinesis, it can’t be deleted (immutability)
- Records can be up to 1MB in size
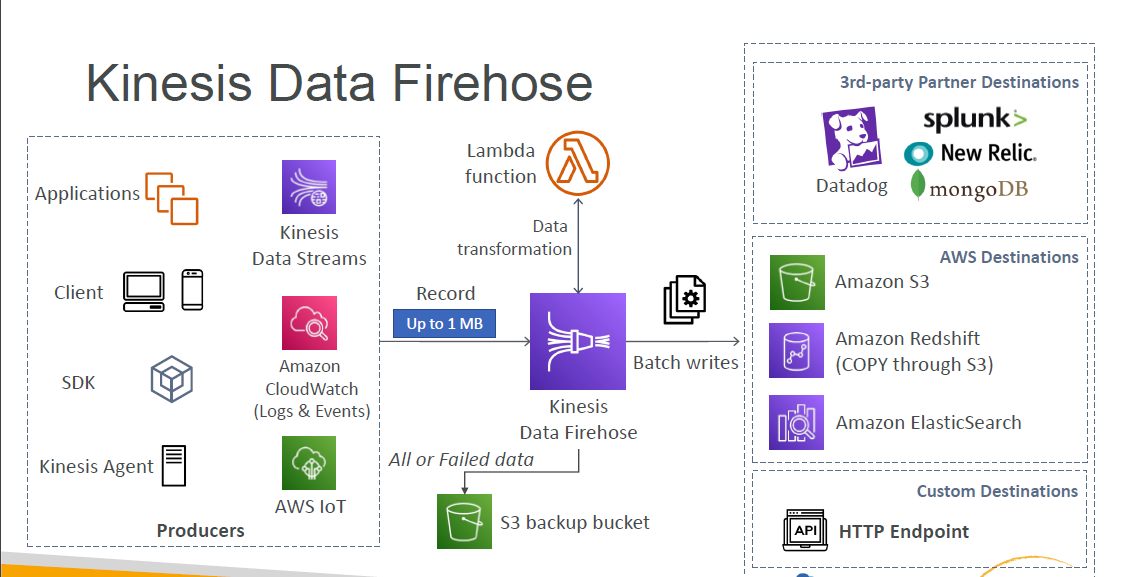
Kinesis Data Firehose
Kinesis Firhose Overview
•Fully Managed Service, no administration •Near Real Time (60 secnds latency minimum for non full batches) •Data Ingestion into Redshift / Amazon S3 / ElasticSearch / Splunk •Automatic scaling •Supports many data formats •Data Conversions from CSV / JSON to Parquet / ORC (only for S3) •Data Transformation through AWS Lambda (ex: CSV => JSON) •Supports compression when target is Amazon S3 (GZIP, ZIP, and SNAPPY) •Pay for the amount of data going through Firehose
Data Streams vs Firehose
Streams •Going to write custom code (producer / consumer) •Real time (~200 ms latency for classic, ~70 m slatency for enhanced fan-out) •Automatic scaling with On-demand Mode •Data Storage for 1 to 365 days, replay capability, multi consumers
Firehose •Fully managed, send to S3, Splunk, Redshift, ElasticSearch •Serverless data transformations with Lambda •Nearreal time (lowest buffer time is 1 minute) •Automated Scaling •No data storage
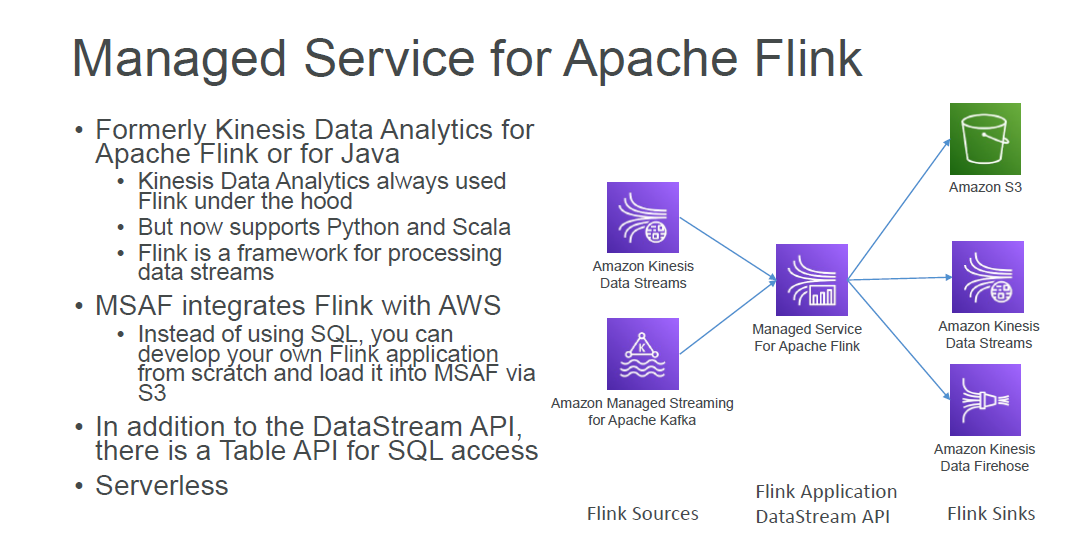
Kinesis Data Analytics
Use cases
•Streaming ETL: select columns, make simple transformations, on streaming data •Continuous metric generation:live leaderboard for a mobile game •Responsive analytics:look for certain criteria and build alerting (filtering)
Features •Pay only for resources consumed (but it’s not cheap) •Serverless; scales automatically •Use IAM permissions to access streaming source and destination(s) •SQL or Flink to write the computation •Schema discovery •Lambda can be used for pre-processing
Kinesis Data Analytics + Lambda
-
Aws Lambda can be a destination aws well
-
Allows lots of flexibility for post-processing
- Ex: send an alert if a certain condition is met
- Ex: send data to a third party service
- Ex: store data in a database
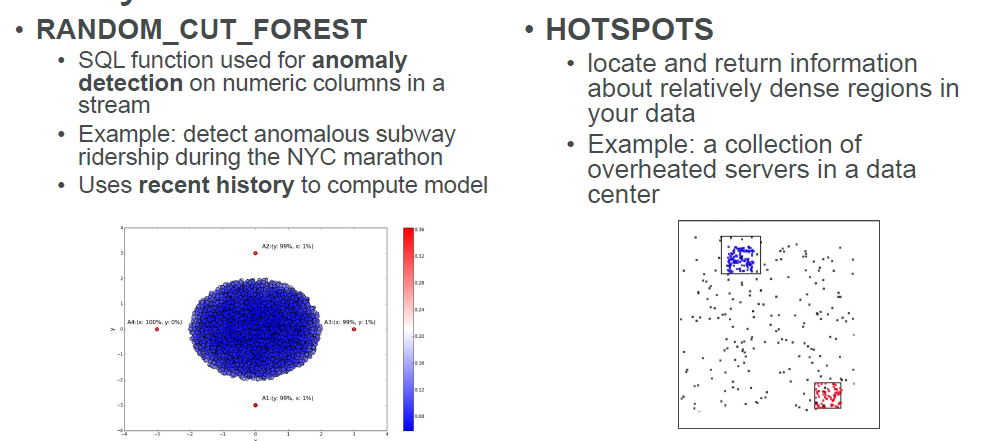
Kinesis Anaylytics
Kinesis Summary - Machine Learning
-
Kinesis Data Streams: real-time data streaming at scale
-
Kinesis Data Firehose: load data streams into AWS data stores near real-time
-
Kinesis Data Analytics: analyze data streams with SQL or Flink
-
Kinesis Video Streams: store and analyze video streams
Glue Data Catalog
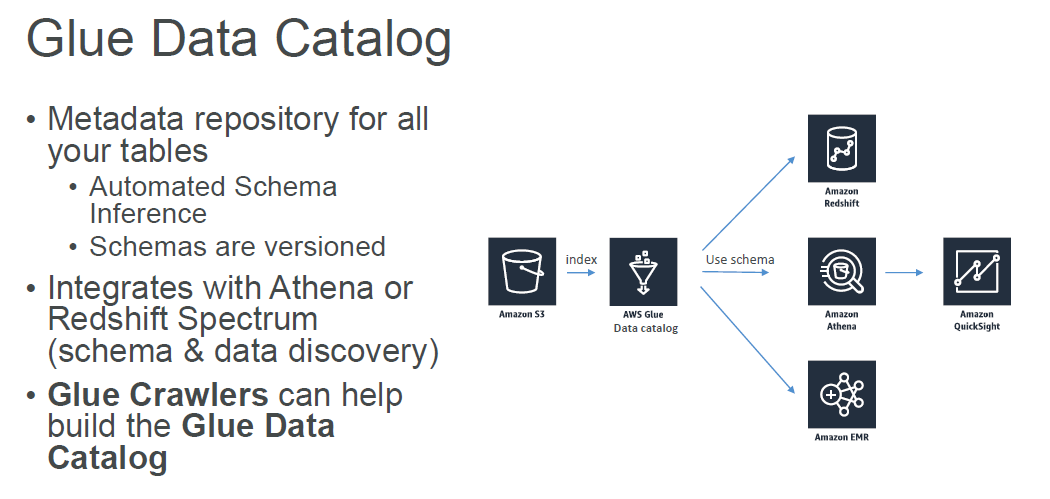
Glue Data Catalog
Crawlers connect to a data store, progresses through a prioritized list of classifiers to determine the schema for your data, and then creates metadata tables in the Data Catalog.
- Works with S3, RDS, Redshift, and any JDBC data store
Why not use python scripts and use Glue and ETL ?
You are nike you have 140 TB of data and you want to do ETL how do you do it?
Downloading 140 TB of data does your computer have enough space? how long will it take?
Even if you have enough space, how long will it take to process 140 TB of data?
That's why you use Glue and ETL because data is already in the cloud because you won't have data center in your office and you are not IBM or Oracle or Microsoft your data is already in the cloud and you want to process it's much faster to use Glue and ETL than to download the data and process it on your computer.
Glue ETL
-
Transforms your data , cleans it, normalizes it, and prepares it for loading into data warehouse
- Fully managed, cost-effective, serverless, and easy to use
- Generate ETL code in Python or Scala , you can modify the code
-
Bundled with a lot of pre-built transformations
- Join, filter, etc
- You can also use your own scripts
- Map - add fields, remove fields, etc
-
Machine Learning Transformations
- Find matches ML : identify duplicate records in your dataset,even when the records don't have a common unique identifier
-
Format Conversion
- Convert data to Parquet or ORC for performance
- Convert data to Apache Avro or JSON for schema evolution
- Convert data to CSV or XML for schema evolution
AWS Glue DataBrew
-
AWS Glue DataBrew is a visual data preparation tool that enables you to clean and normalize data without writing code.
-
Reduces ML and analytics data preparation time by up to 80%.
Database Options


Possible Machine Learning Architecture