Data Analytics Fundamentals
Data Analytics Fundamentals
Introduction
Data analytics is the science of analyzing raw data in order to make conclusions about that information. Many of the techniques and processes of data analytics have been automated into mechanical processes and algorithms that work over raw data for human consumption. Data analytics techniques can reveal trends and metrics that would otherwise be lost in the mass of information.
Benefits of Data Analytics
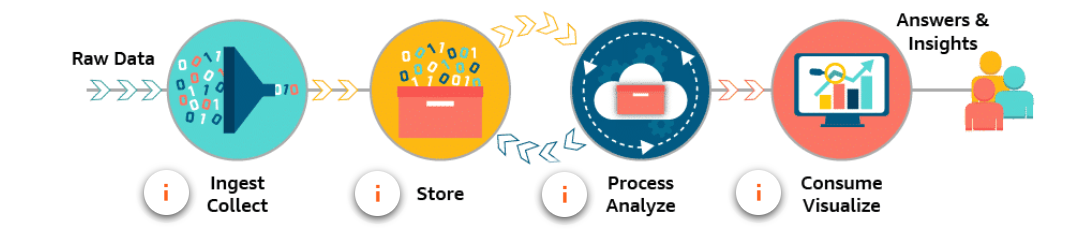
Components of a Data analytics process
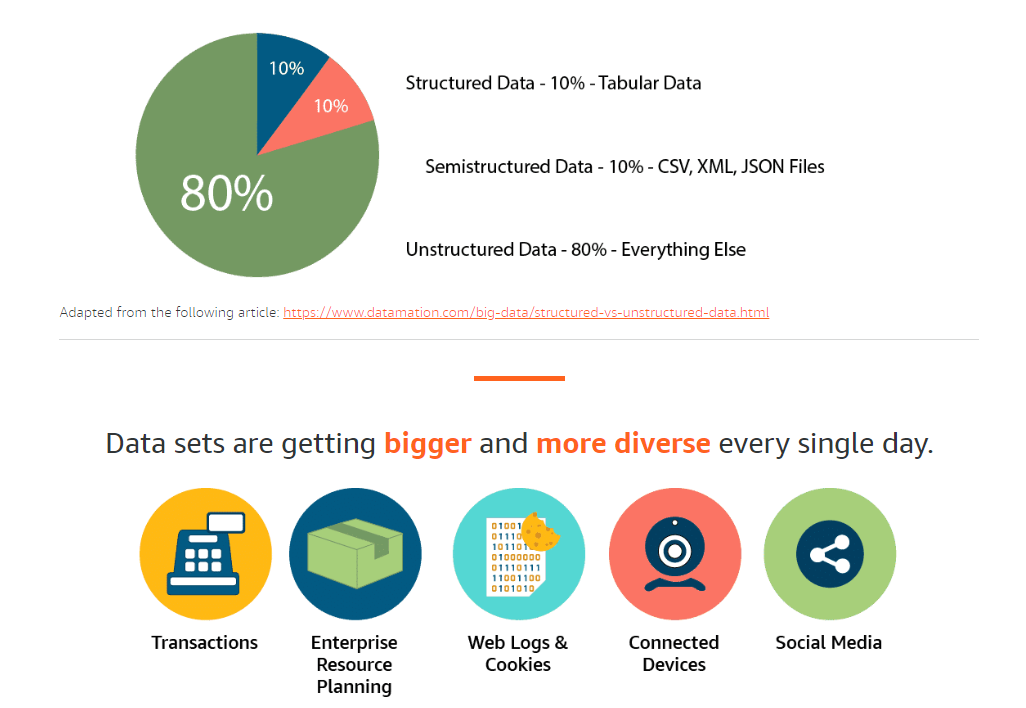
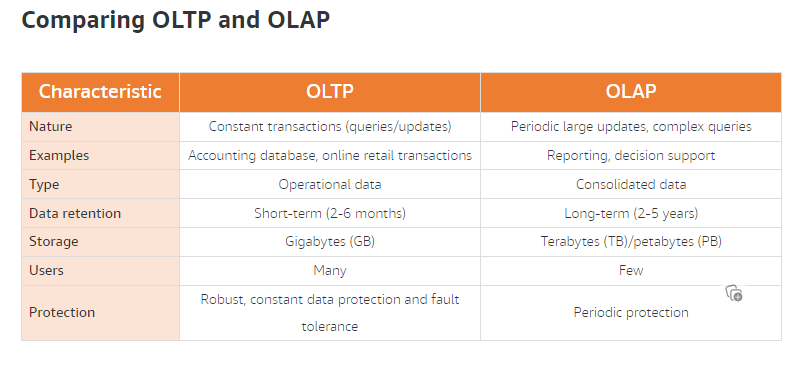
5Vs of Big Data
-
Volume: The amount of data.
-
Velocity: The speed of data processing.
-
Variety: The different types of data.
-
Veracity: The quality of the data.
-
Value: The value of the data.

Volume
Amazon S3 concepts
To get the most out of Amazon S3, you need to understand a few simple concepts. First, Amazon S3 stores data as objects within buckets.
An object is composed of a file and any metadata that describes that file. To store an object in Amazon S3, you upload the file you want to store into a bucket. When you upload a file, you can set permissions on the object and add any metadata.
Buckets are logical containers for objects. You can have one or more buckets in your account and can control access for each bucket individually. You control who can create, delete, and list objects in the bucket. You can also view access logs for the bucket and its objects and choose the geographical region where Amazon S3 will store the bucket and its contents
Data Lakes
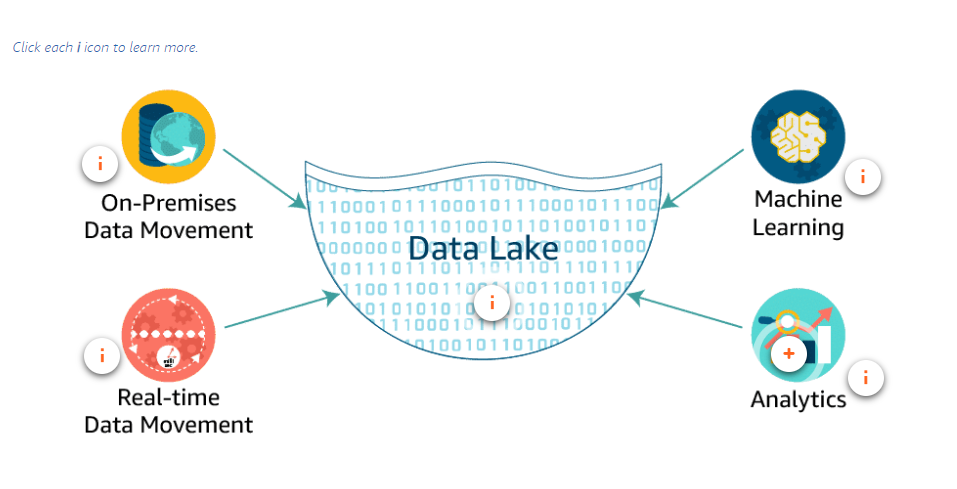

Benefits of a data lake on AWS
-
Are a cost-effective data storage solution. You can durably store a nearly unlimited amount of data using Amazon S3.
-
Implement industry-leading security and compliance. AWS uses stringent data security, compliance, privacy, and protection mechanisms.
-
Allow you to take advantage of many different data collection and ingestion tools to ingest data into your data lake. These services include Amazon Kinesis for streaming data and AWS Snowball appliances for large volumes of on-premises data.
-
Help you to categorize and manage your data simply and efficiently. Use AWS Glue to understand the data within your data lake, prepare it, and load it reliably into data stores. Once AWS Glue catalogs your data, it is immediately searchable, can be queried, and is available for ETL processing.
-
Help you turn data into meaningful insights. Harness the power of purpose-built analytic services for a wide range of use cases, such as interactive analysis, data processing using Apache Spark and Apache Hadoop, data warehousing, real-time analytics, operational analytics, dashboards, and visualizations.
Data Lake on AWS
-
Collect and store any type of data, at any scale, and at low cost
-
Secure the data and prevent unauthorized access
-
Catalog, search, and find the relevant data in the central repository
-
Quickly and easily perform new types of data analysis
-
Use a broad set of analytic engines for one-time analytics, real-time streaming, predictive analytics, AI, and machine learning
Data Lake vs Data Warehouse
-
Data Lake:
- Definition: A data lake is like a real lake, collecting data from multiple sources (referred to as "rivers"). It stores various types of data, including structured, semi-structured, and unstructured data.
- Purpose: Data lakes are designed to capture and store large amounts of raw data. This data can be used for machine learning, artificial intelligence (AI) algorithms, and business purposes. After processing, data from a data lake can also be transferred to a data warehouse.
- Data Type: Raw data of all types, regardless of its source or structure.
- Schema Position: After data storage, offering agility and easy data capture.
- Users: Data scientists and those who need in-depth analysis and tools (such as predictive modeling).
- Accessibility: Accessible and easy to update.
- History: Relatively new for big data¹.
-
Data Warehouse:
- Definition: A data warehouse stores structured data that has been processed for specific purposes. It serves as a repository for already structured data, which can be queried and analyzed.
- Purpose: Data warehouses are organized systems used by business professionals for operations. They provide security and high performance.
- Data Type: Processed data stored according to metrics and attributes.
- Schema Position: Before data storage, ensuring security and performance.
- Users: Business professionals who need structured analytics.
- Accessibility: More complicated to make changes.
- History: The concept has been around for decades.
In summary, data lakes are versatile and accommodate raw data, while data warehouses focus on structured data for specific analytical purposes. Both play crucial roles in managing and utilizing big data effectively. 🌊🏢
For a deeper introduction to data lakes, you can watch this informative video from Google: What is a data lake?
Redshift Spectrum
Amazon Redshift Spectrum is a feature of Amazon Redshift that allows you to run complex SQL queries against exabytes of data in Amazon S3. With Redshift Spectrum, you can extend the analytic power of Amazon Redshift beyond the data that is stored on local disks. Redshift Spectrum directly queries the data in your Amazon S3 data lake. You can use Redshift Spectrum to run SQL queries against your data lake and get results in seconds.
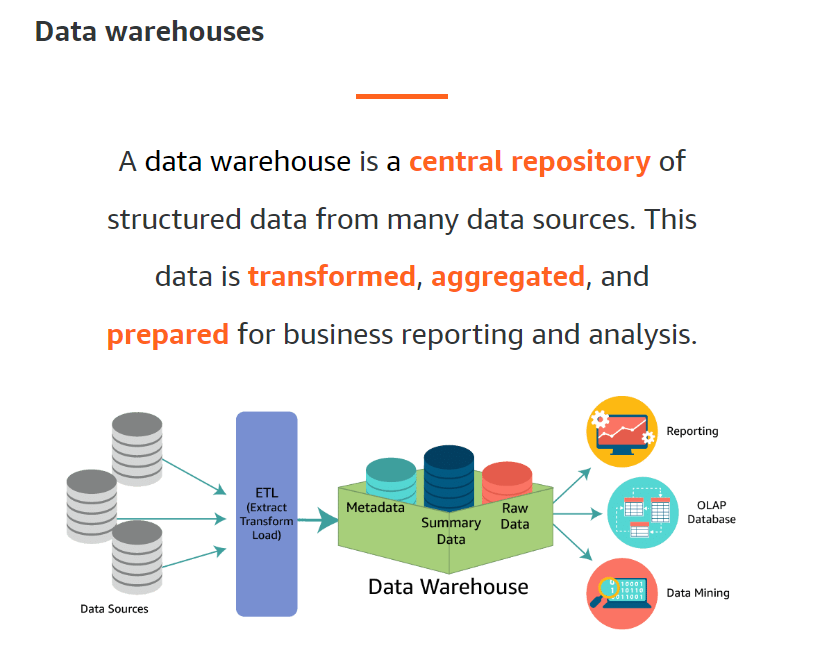
Data Warehouses
Data processing
Data processing means the collection and manipulation of data to produce meaningful information. Data collection is divided into two parts, data collection and data processing.
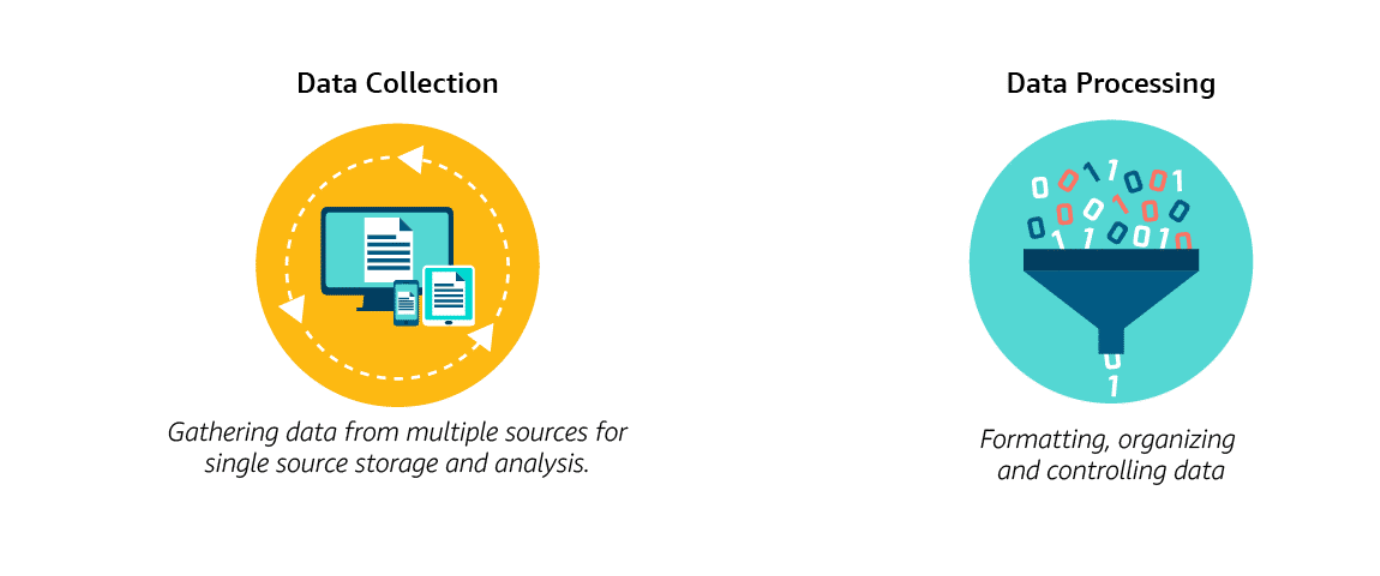

Type of Processing

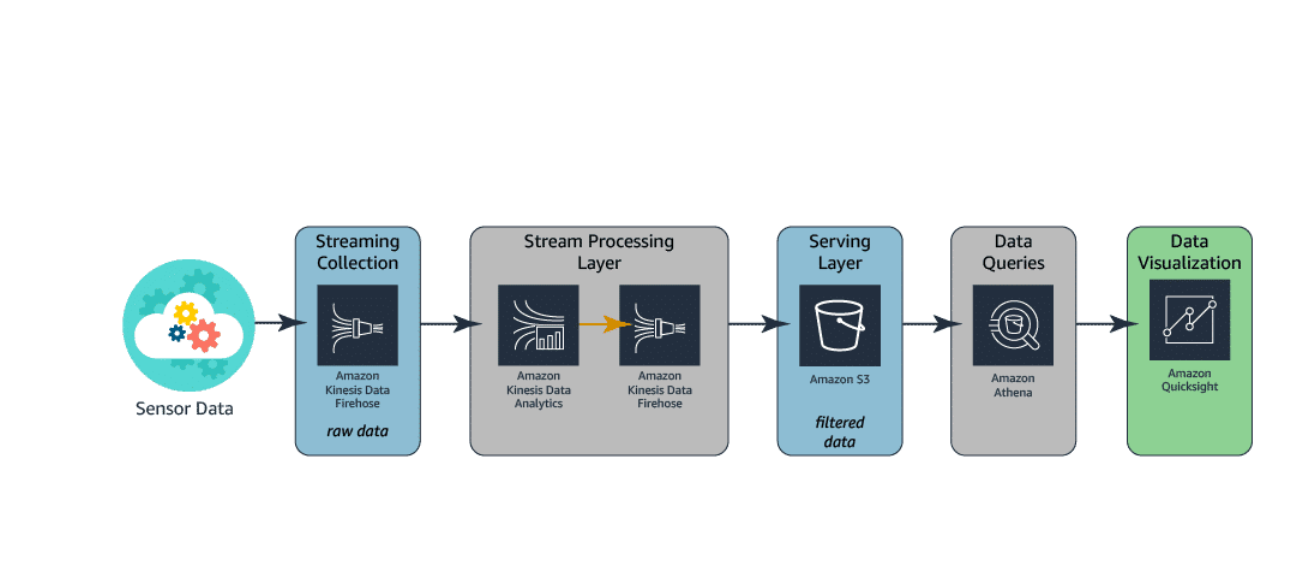
Data Structeures



Varitey
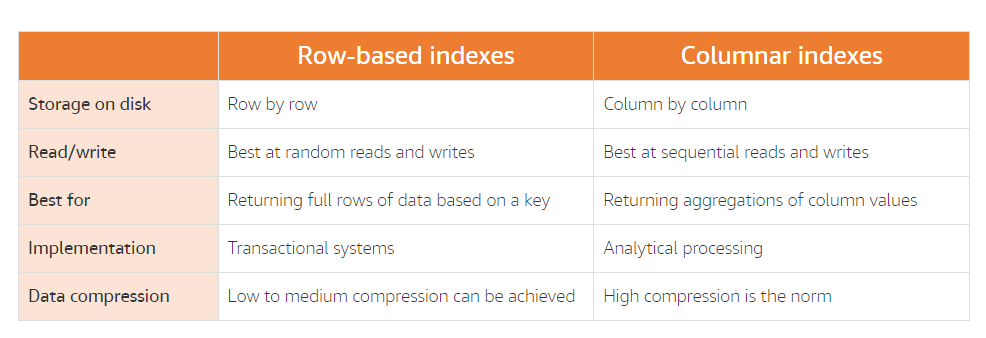
Indexing
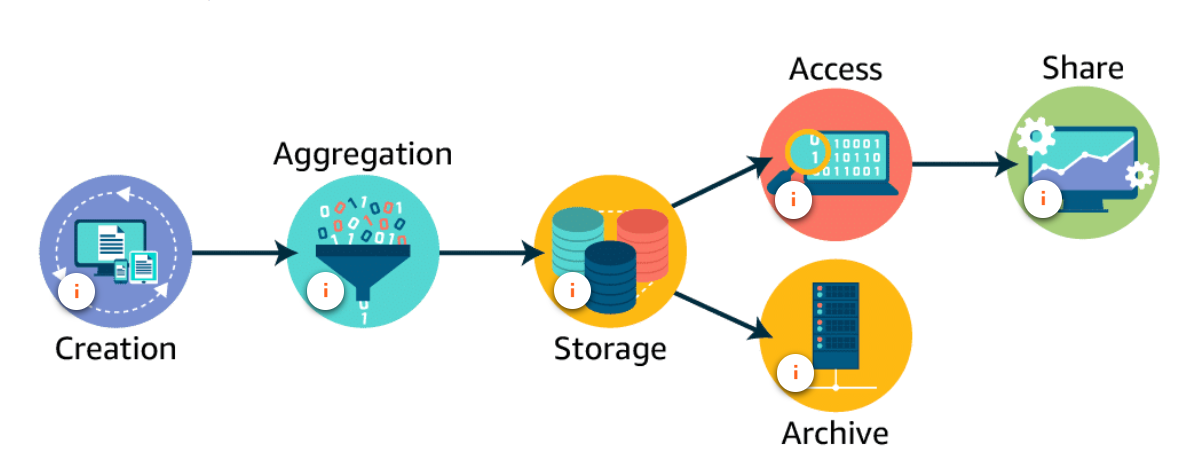
The problem of Veracity
Data changes over time. As it is transferred from one process to another, and through one system and another, there are opportunities for the integrity of the data to be negatively impacted. You must ensure that you maintain a high level of certainty that the data you are analyzing is trustworthy.
integrity

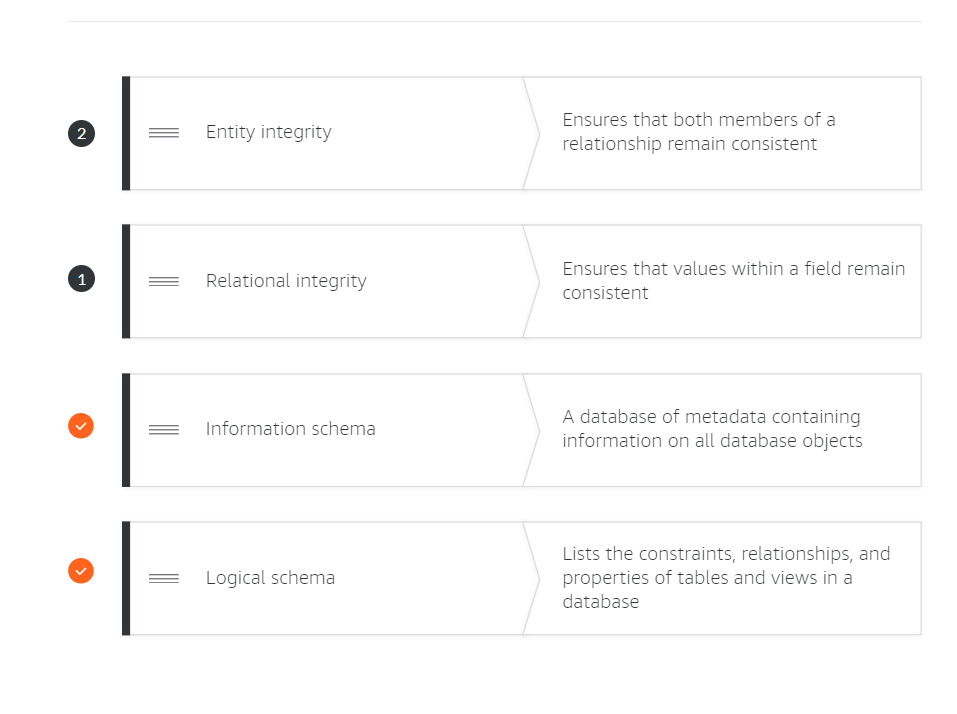
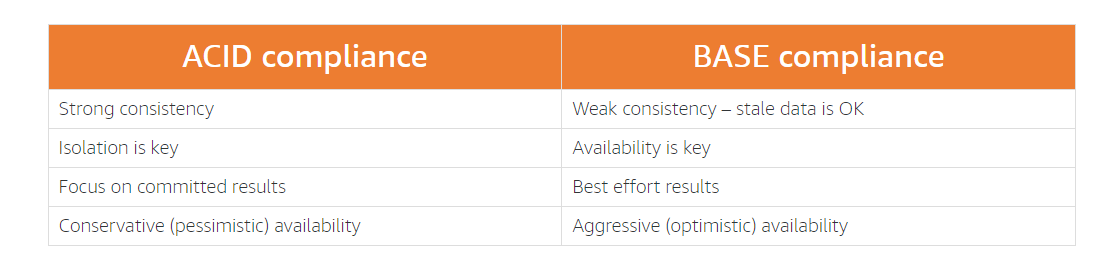
Certainly! Let’s delve into the differences between the ACID and BASE database transaction models:
-
ACID (Atomicity, Consistency, Isolation, Durability):
- Atomicity: Each transaction is either fully executed or completely rolled back. If any part of a transaction fails, the entire transaction is aborted, ensuring data consistency.
- Consistency: Transactions maintain the structural integrity of the database. Valid states are preserved, and no invalid data is allowed.
- Isolation: Transactions are isolated from each other. They cannot interfere with one another while in progress.
- Durability: Completed transactions persist even in the face of network or power failures. Data remains intact.
- Use Case Example: Financial institutions heavily rely on ACID databases for secure money transfers, where atomicity ensures that funds are either fully debited or credited without discrepancies. Common ACID-compliant databases include MySQL, PostgreSQL, Oracle, SQLite, and Microsoft SQL Server1.
-
BASE (Basically Available, Soft state, Eventually consistent):
- Basically Available: BASE prioritizes high availability over immediate consistency. It acknowledges that temporary inconsistencies may occur during distributed system operations.
- Soft State: Unlike ACID, BASE allows transient inconsistencies. The system can be in an intermediate state during updates or failures.
- Eventually Consistent: Over time, the system converges to a consistent state. It doesn’t guarantee immediate consistency but ensures eventual correctness.
- Use Case Example: NoSQL databases often follow the BASE model. These databases handle large-scale data, trading off strict consistency for scalability and availability. Examples include Apache CouchDB and IBM Db21.
Types of Data Analytics




